Proto Successor Measure: Representing the Behavior Space of an RL Agent
| * Equal Contribution |
† Equal Advising |
| 1 The University of Texas at Austin |
2 Sony AI |
|
Abstract
Having explored an environment, intelligent agents should be able to transfer their knowledge to most downstream tasks within that environment without additional interactions.
Referred to as "zero-shot learning", this ability remains elusive for general-purpose reinforcement learning algorithms.
While recent works have attempted to produce zero-shot RL agents, they make assumptions about the nature of the tasks or the structure of the MDP.
We present Proto Successor Measure: the basis set for all possible behaviors of a Reinforcement Learning Agent in a dynamical system.
We prove that any possible behavior (represented using visitation distributions) can be represented using an affine combination of these policy-independent basis functions.
Given a reward function at test time, we simply need to find the right set of linear weights to combine these bases corresponding to the optimal policy.
We derive a practical algorithm to learn these basis functions using reward-free interaction data from the environment and show that our approach can produce the optimal policy at test time for any given reward function without additional environmental interactions.
Background
Consider a discounted reward-free MDP $\mathcal{M}=(\mathcal{S},\mathcal{A},P,\gamma)$. For a policy $\pi$, define the visitation distribution $d^{\pi}$:
$$d^{\pi}(s,a) = (1-\gamma)\sum_{t=0}^{\infty}\gamma^t\Pr^{\pi}(s_t=s,a_t=a).$$
Similarly define the Successor Measure $M^{\pi}$ as:
$$M^{\pi}_{\gamma}(s,a,s^+, a^+) = (1-\gamma)\sum_{t=0}^{\infty}\gamma^t\Pr^{\pi}(s_t=s^+, a_t=a^+|s_0=s,a_0=a).$$
For reward $r(s,a)$, the linear program for the optimal policy is:
$$J_r(\pi)=\mathbb{E}_{(s,a)\sim d^{\pi}}[r(s,a)] = \langle r, d^{\pi} \rangle.$$
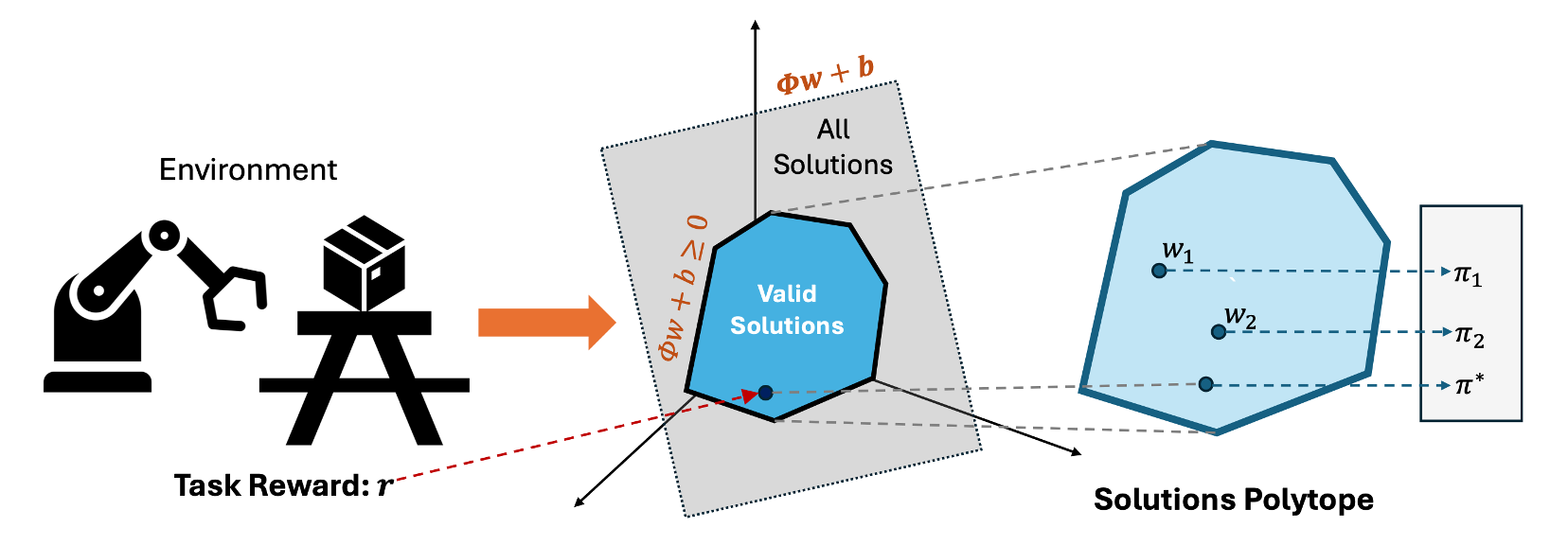
Thus, control over rewards reduces to selecting the right occupancy $d^{\pi}$ from the feasible occupancy set.
Proto Successor Measure
Any visitation distribution $d^{\pi}$ or successor measure $M^\pi$ is a solution of the Bellman flow constraints:
$$\sum_a d(s,a) = (1-\gamma)\mu(s) + \gamma\sum_{s',a'}P(s|s',a')d(s',a')$$
$$\sum_{a'}M(s,a,s^+, a^+) = (1-\gamma) \delta(s^+ = s, a^+ = a) + \gamma\sum_{s',a'}P(s^+|s',a')M(s,a,s', a')$$
Any successor measure, $M^\pi$ in an MDP forms an affine set and so can be represented as
$M^{\pi} = \sum_{i=1}^d \phi_i w_i + b$ where $\phi_i$ and $b$ are independent of the policy $\pi$ and $d$ is the dimension of the affine space.