|
I am a fourth year Ph.D. student in the Computer Science Department at University of Texas at Austin, working with Prof. Amy Zhang and Prof. Peter Stone. I am interested in utilizing reward-free transitions for improving reinforcement learning be it through designing principled representation learning techniques or downstream algorithms independent of rewards. For this I have been looking at RL from the perspective of visitation distributions and utilizing unsupervised RL, goal-conditioned RL and distribution matching learning techniques. Previously, I completed my Dual Degree (B.Tech. + M.Tech.) in Computer Science and Engineering from the Indian Institute of Technology Kharagpur with a department rank 1. During my undergrad, I was a leading member of the Autonomous Ground Vehicles research group where I worked on a number of perception and planning projects for autonomous driving. I completed my bachelor thesis on "Reinforcement Explanation Learning" under the supervision of Prof. Abir Das.
|

|
|
|
|
Harshit Sikchi*, Siddhant Agarwal*, Pranaya Jajoo*, Samyak Parajuli*, Max Rudolph*, Peter Stone, Amy Zhang, Scott Niekum * denotes equal contribution Under Submission ICML 2025 project page / paper We introduce a framework for unsupervised RL to produce optimal policies for any language instruction. |
|
Siddhant Agarwal*, Harshit Sikchi*, Peter Stone, Amy Zhang * denotes equal contribution Under Submission ICML 2025 project page / paper We provide a representation that can produce optimal policies for any reward function in the environment. |

|
Adam Labiosa∗, Zhihan Wang∗, Siddhant Agarwal, William Cong, Geethika Hemkumar, Abhinav Narayan Harish,Benjamin Hong, Josh Kelle, Chen Li, Yuhao Li, Zisen Shao, Peter Stone, Josiah P. Hanna * denotes equal contribution, authors in alphabetical order ICRA 2025 project page / paper / code The Robotics stack used by our RoboCup Standard Platform League that used RL to train high level abstracted robotics behavior. |
|
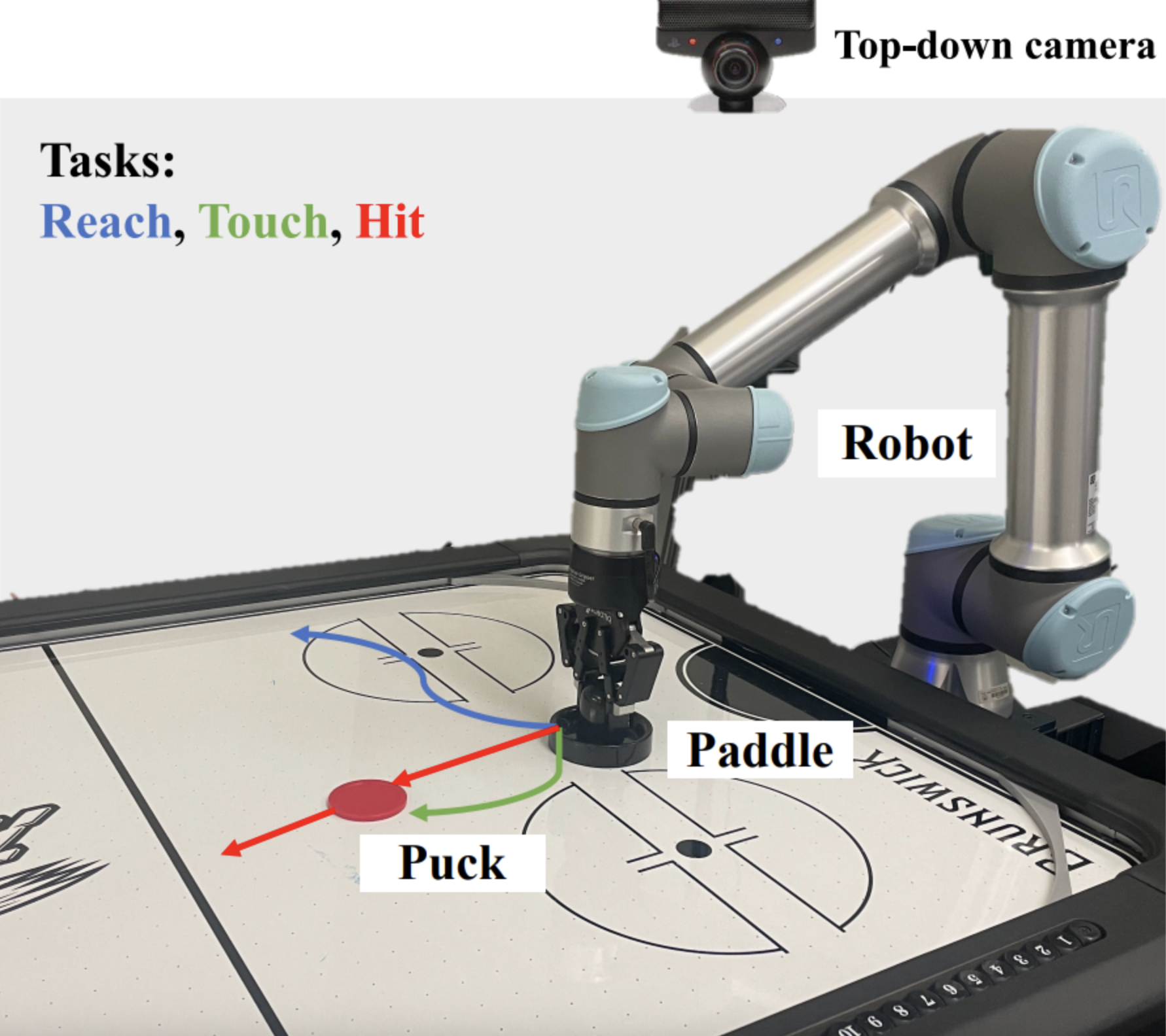
Caleb Chuck∗, Carl Qi∗, Michael J. Munje∗, Shuozhe Li∗, Max Rudolph∗, Chang Shi∗, Siddhant Agarwal∗, Harshit Sikchi∗, Abhinav Peri, Sarthak Dayal, Evan Kuo, Kavan Mehta, Anthony Wang, Peter Stone, Amy Zhang, Scott Niekum * denotes equal contribution CRA Workshop Manipulation Skills, 2024 project page / paper / code A two stage simulator and real-world manipulator system designed as a air-hockey for to study effects of RL and IL. |
|
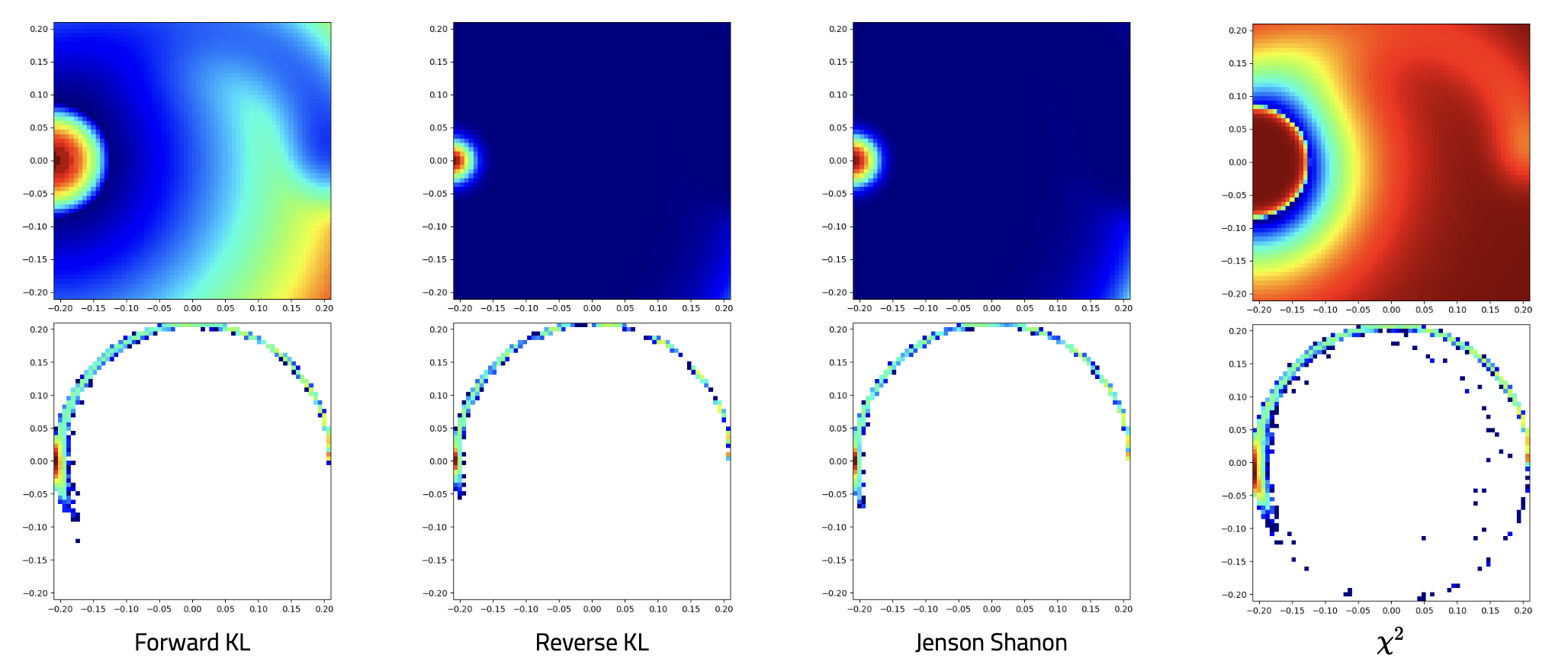
Siddhant Agarwal, Ishan Durugkar, Peter Stone, Amy Zhang NeurIPS 2023 project page / arXiv / code We introduce a general framework for goal conditioned RL using f-divergences. |
|
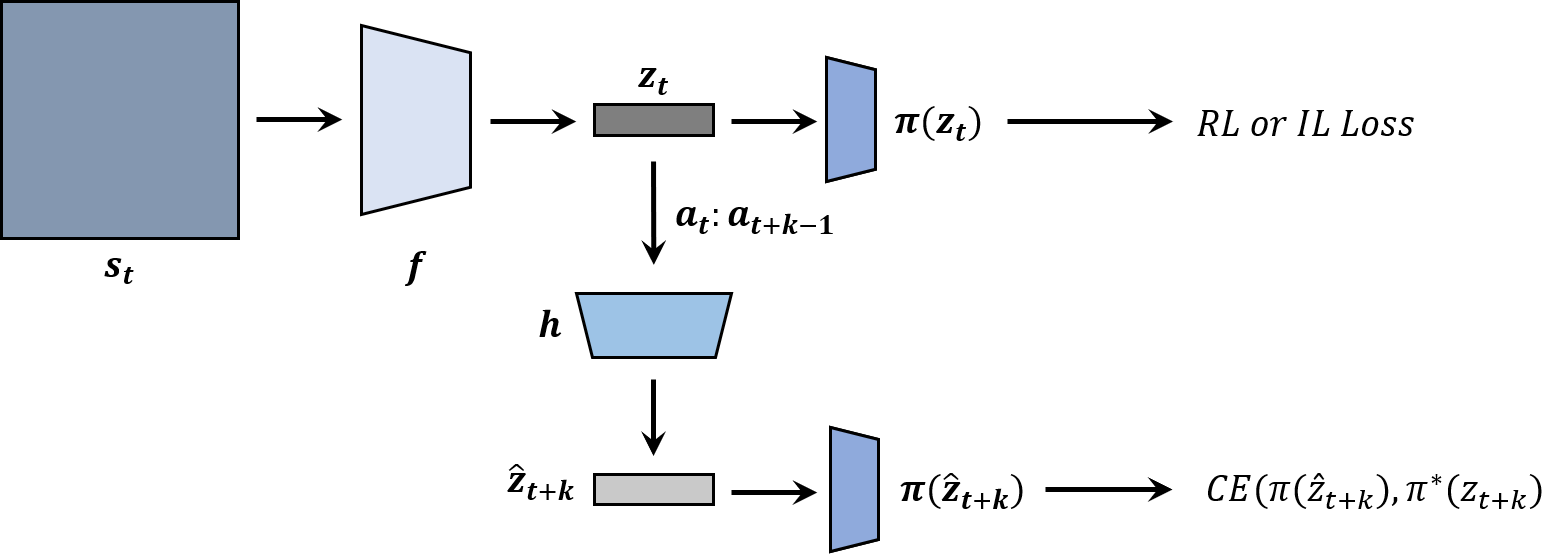
Siddhant Agarwal, Aaron Courville, Rishabh Agarwal NeurIPS 2021 workshop on Deep Reinforcement Learning and Ecological Theory of RL project page / paper / We introduce latent representations that can predict the behavior of the agent at future steps to improve generalization in RL. |
|
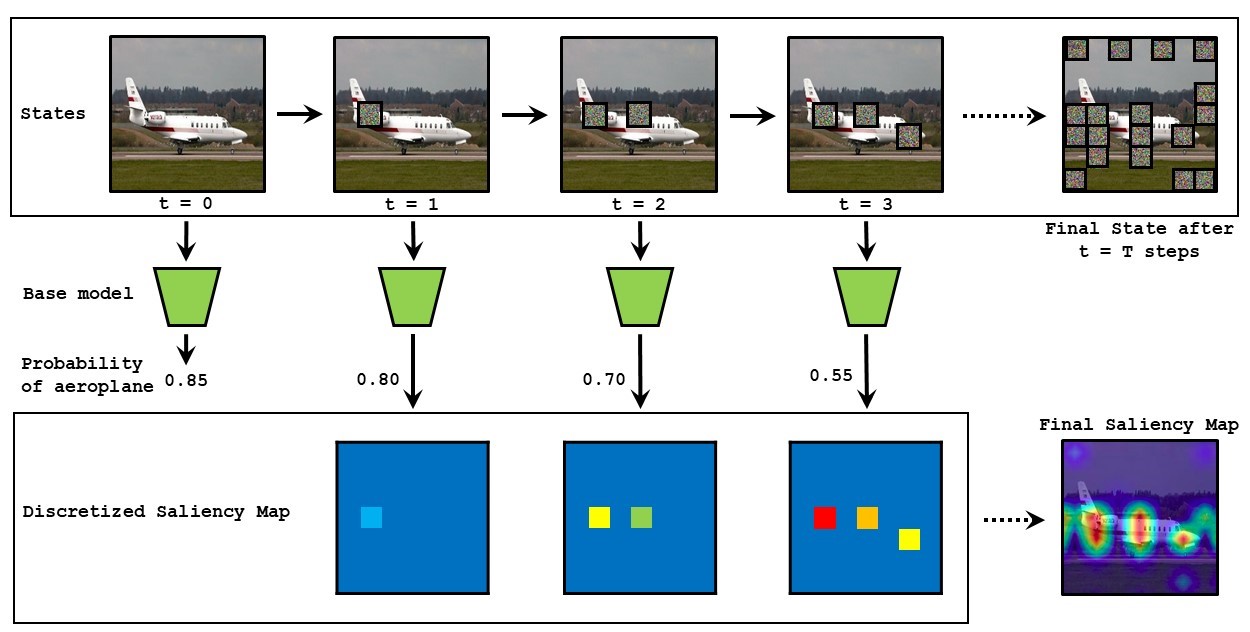
Siddhant Agarwal, Owais Iqbal, Sree Aditya Buridi, Mada Manjusha, Abir Das NeurIPS 2021 workshop on eXplainable AI approaches for debugging and diagnosis project page / arXiv / code We reformulate the process of generating saliency maps using perturbation based methods for black box models as a Markov Decsion Process and use RL to optimally search for the best saliency map, thereby reducing the inference time without hurting the performance. |

|
Minjie Sun, Siddhant Agarwal, Zico Kolter ICLR 2021 workshop on Security and Safety in Machine Learning systems. project page / arXiv / code We show that backdoored classifiers can be attacked by anyone rather than only the adversary. We propose an attack that generates alternate triggers for the poisoned classifiers. |
|
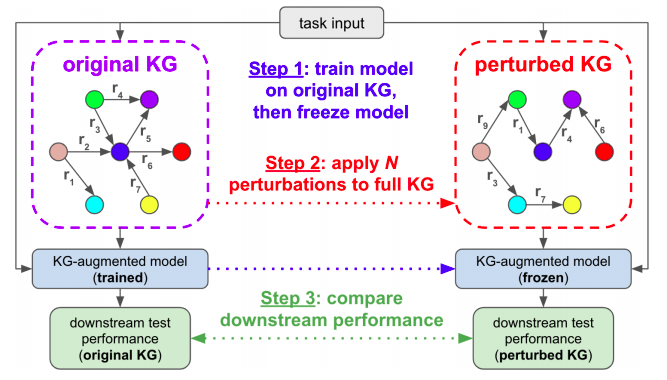
Mrigank Raman, Aaron Chan*, Siddhant Agarwal*, Peifeng Wang, Hansen Wang, Sungchul Kim, Ryan Rossi, Handong Zhao, Nedim Lipka, Xiang Ren * denotes equal contribution International Conference of Learned Representations 2021 and NeurIPS 2020 workshop on Knowledge Representation and Reasoning in Machine Learning [Best paper nomination] project page / arXiv / code We show that using reinforcement learning (or even simple heuristics) we can produce deceptively perturbed knowledge graphs that preserve the downstream performance of the kg-aumented models. |

|
Rishabh Madan*, Deepank Agrawal*, Shreyas Kowshik*, Harsh Maheshwari*, Siddhant Agarwal*, Debashish Chakravarty * denotes equal contribution, dice roll International Conference on Pattern Recognition Application and Methods, Prague, 2019 project page / paper / We use a hybrid CNN archticture that uses two image processing features to classify the images. The CNN architecture has significantly less number of parameters than any of the state of the art methods on GTSRB. |
|
|

|
project page / We worked to develop vision, planning and localization modules for a category 4 autonomous vehicle. |
|
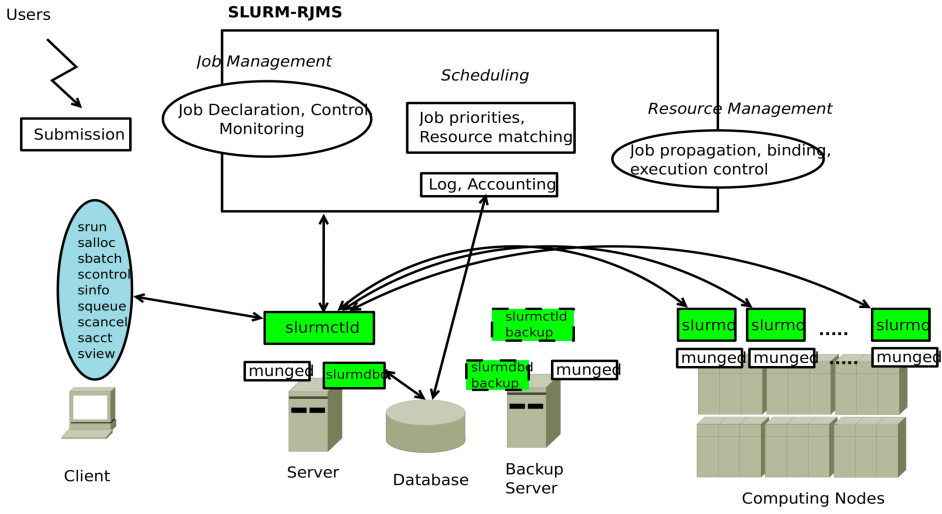
project page / report / code We investigate commonly used cluster management systems like SLURM and Condor. We further develop a fault-tolerant active-passive SLURM-like cluster management system. |
|
project page / report / code We use parallization in a GPU to accelarate graph algorithms like BFS, DFS and Single Source Shortest Path and All Pair Shortest Path to achieve massive speedups. |

|
project page / presentation / code We develop an android chatbot application using a trained LSTM based encoder-decoder module trained for emotion specific chats. We use a simple classifier to choose the appropriate model from the chat. |
|
Webpage template courtesy: Jon Barron |